声明:本篇文章除部分引用外,均为原创内容,如有雷同纯属巧合,引用转载请附上原文链接与声明。
阅读条件:读本篇文章需掌握java集合基础知识、Stream基本语法与使用、函数式接口、lambda表达式、泛型知识、lombok插件使用、guava基础集合工具使用、java8双冒号的使用。
注:本文若包含部分下载内容,本着一站式阅读的想法,本站提供其对应软件的直接下载方式,但是由于带宽原因下载缓慢是必然的,建议读者去相关官网进行下载,若某些软件禁止三方传播,请在主页上通过联系作者的方式将相关项目进行取消。
参考引用
文章大纲
- Stream基础收集功能演示
- Stream收集原理分析
- Collectors.toList()、Collectors.toMap()、Collectors.toSet()源码分析
- Collectors.joining()源码分析
- Collectors.reducing()源码分析
- 自定义Stream收集器演示
一.Stream基本收集功能演示
public void testStream() {
Student s1 = new Student("s1", 1, 20);
Student s2 = new Student("s2", 2, 24);
Student s3 = new Student("s3", 3, 26);
List<Student> students = Lists.newArrayList(s1, s2, s3);
// 将students Stream化处理
List<String> names = students.stream()
// 只取年龄大于23的元素,即保留:s2,s3
.filter(stu -> stu.getAge() > 23)
// 获取将Stream流中Student元素中的姓名组成新的Stream流
.map(Student::getName)
// 将Stream流收集为List集合中
.collect(Collectors.toList());
// names 进行挨个打印 结果为:s2 , s3
names.forEach(System.out::println);
}
@Data
@AllArgsConstructor
public class Student {
private String name;// 姓名
private Integer stuNo; // 学号
private Integer age; // 年龄
}
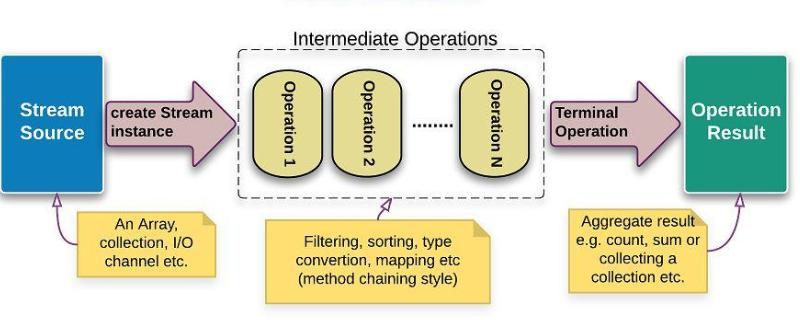
在上述例子中,从结果的角度,该例是通过stream提供的api取得了students集合中的元素年龄大于23的姓名构成的新集合。从过程的角度主要分为以下几步:
- 将然后调用students.stream()将其转换为Stream流准备进行后续处理;
- 调用filter(Predicate predicate)将stream流中的元素进行过滤:仅保留age > 23的元素
- 调用map(Function mapper)将stream流中的元素进行包装:取得student的name取代原Stream流中的元素
- 调用collect(Collector collector)将Stream元素进行收集,按照传入的Collector规则进行收集:Collectors.toList()返回的Collector是将Stream流中的元素收集为List集合。
二.Stream收集原理分析
Collectors.toList()返回了一个已初始化完 成的Collector实例,查看Collectors.toList()方法,可以看到该方法实现如下:
public static <T> Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>(
(Supplier<List<T>>) ArrayList::new,
List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
可以看到该方法返回了一个CollectorImpl对象,CollectorImpl类是Collectors的静态内部类,实现了Collector接口。接下来再查看CollectorImpl类及其对应的构造方法,如下:
static class CollectorImpl<T, A, R> implements Collector<T, A, R> {
private final Supplier<A> supplier;
private final BiConsumer<A, T> accumulator;
private final BinaryOperator<A> combiner;
private final Function<A, R> finisher;
private final Set<Characteristics> characteristics;
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A,R> finisher,
Set<Characteristics> characteristics) {
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
}
可以看到CollectorImpl构造需要三个泛型,我们将挨个讨论这三个泛型所指定的类型,且存在两个构造函数,但实际上都是调用的第一个构造函数进行的初始化,这里笔者先介绍第一个构造函数。可以看到初始化CollectorImpl需要5个参数,分别为:
- Supplier supplier:提供元素容器 泛型 A 表示容器类型
- BiConsumer<A, T> accumulator:将Stream流中的元素累加到容器中 泛型 T 表示Stream流中远射类型
- BinaryOperator combiner:将多个容器合并为一个容器
- Function<A,R> finisher:将最后累加完成后且合并为最后成的最后一个容器进行转换,转换为结果集,泛型 R 表示调用Collect方法后最后返回的类型,也就是最终的结果类型
- Set
characteristics:Collector接口中定义的枚举常量。可以先暂时不做考虑,后续将进行讨论。
Stream流中的元素可以理解为基本有序,其顺序与调用Stream方法对象中的顺序相同,再调用Collect方法时实则是将Stream流中的元素进行处理并收集。Collector实现由Stream流转换为 R 类型结果集。其具体流程如下:
- 首先调用supplier.get(),创建新的元素容器A a,可能会多次调用创建多个元素容器,也可能只会创建一个,这取决于Stream流是否支持并行处理及其他情况
- 对将Stream流中所有的元素调用accumulator.accept(A a,T t)方法,a为通过supplier创建的容器,t为Stream流中的元素
- 在Stream流中每一个元素均调用了accumulator.accept(A a,T t)方法后即累加到元素容器中后,调用combiner.apply(A a1,A a2)方法合并两个容器并返回一个新的A类型容器,该容器将作为下一步combiner.apply(A a1,A a2)方法新的入参,直到合并到最后容器数量只有最后一个的情况下该步骤才结束
- 调用finisher.apply(A a) 方法,对最终的A类型容器进行最后的处理,返回R类型的最终结果。
上述流程是表述了由Stream流转换为R类型最终结果的过程,直接理解可能较为抽象。下面将对Collectos.toList()、Collectos.toMap()、Collectos.toSet()源码进行分析,并结合上述流程进行讲解以加强理解。
三.Collectors.toList()、Collectors.toMap()、Collectors.toSet()源码分析
3.1 Collectors.toList()返回的Collector实现如下:
public static <T> Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>(
// supplier
(Supplier<List<T>>) ArrayList::new,
// accumulator
List::add,
//combiner
(left, right) -> { left.addAll(right); return left; },
// finisher
i -> (List<T>) i,
// characteristics
CH_ID);
}
结合大纲二讨论的流程,我们详细分析Collectors.toList()所返回的Collector的执行流程,从方法签名上看,该方法定义的Stream元素类型(T)为T ,而容器类型(A)定义为未知类型(从supplier的实现上看是List
- supplier
实现为:(Supplier<List>) ArrayList::new;表明创建容器时,是通过该supplier的是返回了一个ArrayList 作为容器 - accumulator
实现为:List::add(不明白双冒号的使用请参考本文的引用参考);表明在累加Stream元素进入容器时,是调用的Supplier提供的ArrayList容器调用add方法将Stream元素添加到ArrayList容器中。 - combiner
实现为:(left,right) -> {left.addAll(right); return left;};表明当两个容器进行合并时,将右边容器的全部元素加入左边容器,并且返回左边的容器参与下一次容器合并。 - finisher
实现为:i -> (List) i;表明对最后的A类型容器直接强制转换为List 类型的,而A类型本质为ArrayList 类型,所以直接转换是没有问题的。
根据大纲二所讨论流程详细讨论:
- 首先调用supplier.get()方法得到一个或多个ArrayList
容器(假设容器名为a,b,c...) - 对Stream流中的所有元素调用accumulator.apply(a,t),即a.add(t),将Stream流中的元素添加进容器a中
- 在将Stream流中的元素均累加到容器中后(此时可能有多个容器,也可能只有一个,只初始化一个容器的情况下不会进入该流程,即不需要合并容器,直接进行下一步,这里假定存在多个容器,需要进行容器合并合并合并为一个),调用combiner.apply(a,b),在其具体实现为:a.addAll(b);return a;容器a被返回参与下一步合并操作,知道合并为只有最后一个容器(假定容器名为d)
- 将最后的容器的类型转换为所需要的结果类型(List
),因为容器d的类型为ArrayList 类型,所以根据finisher的实现:i -> (List )i; 即:d -> (List )d ;即强制转换然后返回为最终结果,按照上述流程,该ArrayList中包含了Stream流中的所有元素,即是Stream流中的元素组成的集合。
思考:Collectors.toList()为什么需要如此实现Collector?
从Collector.toList()实现的Collect可以看出来,其功能是将Stream流中的元素累加到一个List集合中。他的实现原理如下:
- 提供ArrayList容器(一个,或多个)
- 将Stream中的元素添加到ArrayList容器中
- 将生成的ArrayList容器进行合并,最终合并为一个ArrayList容器
- 从实现上,该ArrayList容器就是所需要的结果,而finisher是将最后这个容器进行最后的变换,所以只需要强制转换以下即可
3.2 Collectors.toMap()
Collectors.toMap()返回了一个已初始化完成的Collector实例,查看Collectors.toMap()方法源码,可以看到该方法实现如下:
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) ->
map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
首先从入参上看需要4个参数(本质上是5个,finisher采用的默认的强制转换finisher),比toList(),toSet()多一个入参,原因就是因为需要对Stream流中的元素进行key,value操作。其次,可以看到,入参中的keyMapper和valueMapper实际上组成了accumulator,所以本质上和仍然是4个入参,accumulator需要完成的功能需要由keyMapper和valueMapper配合共同完成。其实现也如代码所示,针对Stream中的元素获取key,value,并且当key出现重复时执行mergeFunction策略。
在jdk 8中,toMap()其实有一个小bug,初始化toMap()时,有三个初始化方法如图所示。在上面的源码中展示的最终的调用函数。

在第一个初始化方法中,只需要传入keyMapper和valueMapper,实际上使用的是Collectors中默认的mergeFunction(throwingMerger()),该处理策略是只要有相同的key,则抛出异常;但是抛出的异常信息实际上提示的是重复的key下对应的值。
该bug在open JDK的bug编号为:JDK-8040892
Incorrect message in Exception thrown by Collectors.toMap(Function,Function)
在jdk 9中才进行的修复:JDK-8173464
Wrong exception message when collecting a stream to a map
Pallavi Sonal added a comment - 2017-01-27 00:42
This has been fixed in JDK 9 with JDK-8040892.
In JDK8 versions, it throws the wrong message i.e. instead of Duplicate key, it shows Duplicate key .
3.3 Collectors.toSet() 源码分析
要实现toSet(),原理同toList(),只需要改变初始化容器Supplier
四.Collectors.joining()源码分析
Collectors.joining()有三个初始化方法,如图所示。

点开源码会发现,第三种方法初始化实际上是第一种。第二种与其他两种初始化方法不一致。内部实现只是简单的采用了StringBuilder作为supplier容。而第一种采用的StringJoiner来实现,相比较无参初始化方法,第一种稍微复杂一点,但实际上原理是一样的,这里笔者分析并介绍第一种初始化方法。其源码如下:
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,CharSequence prefix,CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}
可以看到,Supplier容器为StringJoiner(delimiter,prefix,suffix),accumulator为StringJoiner::add,combiner为StringJoiner::merge,finisher为StringJoiner::toString。
依次查看上述方法;
supplier:
public StringJoiner(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
Objects.requireNonNull(prefix, "The prefix must not be null");
Objects.requireNonNull(delimiter, "The delimiter must not be null");
Objects.requireNonNull(suffix, "The suffix must not be null");
// make defensive copies of arguments
this.prefix = prefix.toString();
this.delimiter = delimiter.toString();
this.suffix = suffix.toString();
this.emptyValue = this.prefix + this.suffix;
}
accumulator :
public StringJoiner add(CharSequence newElement) {
prepareBuilder().append(newElement);
return this;
}
prepareBuilder:
private StringBuilder prepareBuilder() {
if (value != null) {
value.append(delimiter);
} else {
value = new StringBuilder().append(prefix);
}
return value;
}
combiner :
public StringJoiner merge(StringJoiner other) {
Objects.requireNonNull(other);
if (other.value != null) {
final int length = other.value.length();
// lock the length so that we can seize the data to be appended
// before initiate copying to avoid interference, especially when
// merge 'this'
StringBuilder builder = prepareBuilder();
builder.append(other.value, other.prefix.length(), length);
}
return this;
}
finisher :
public String toString() {
if (value == null) {
return emptyValue;
} else {
if (suffix.equals("")) {
return value.toString();
} else {
int initialLength = value.length();
String result = value.append(suffix).toString();
// reset value to pre-append initialLength
value.setLength(initialLength);
return result;
}
}
}
可以看到,在Collector.join(delimiter,prefix,suffix)方法实际上是利用StrongJoinner来完成的将多个Charsequence合并为一个。需要注意的是,finisher在执行的时候,实际上是调用的StringJoiner的toString方法,当suffix存在时,需要保证(通过initialLength来实现)真实的value不要append suffix,这样就可以多次调用,结果都是正确的。同理Collector.join()方法,是StringBuilder来实现,更为简单。
五、Collectors.reducing()源码分析
待更新
六、自定义Stream收集器演示
待更新
